Page load time and crawl budget rank will be the most important SEO indicators in 2020
Based on my own testing, PLT and CBR are the technical aspects I believe will determine website success, or failure, in the new year.
Max Cyrek on December 23, 2019 at 9:10 am
- More
Google has the ability to impose its own rules on website owners, both in terms of content and transparency of information, as well as the technical quality. Because of this, the technical aspects I pay the most attention to now – and will do so next year – are the speed of websites in the context of different loading times I am calling PLT (Page Load Time).
Time to first byte (TTFB) is the server response time from sending the request until the first byte of information is sent. It demonstrates how a website works from the perspective of a server (database connection, information processing and data caching system, as well as DNS server performance). How do you check TTFB? The easiest way is to use one of the following tools:
- Developer tools in the Chrome browser
- WebPageTest
- Byte Check
Interpreting results
TTFB time below 100ms is an impressive result. In Google’s recommendations, TTFB time should not exceed 200ms. It is commonly adopted that the acceptable server response time calculated to receiving the first byte may not exceed 0.5s. Above this value, there may be problems on a server so correcting them will improve the indexation of a website.
Improving TTFB
1. Analyze the website by improving either the fragments of code responsible for resource-consuming database queries (e.g. multi-level joins) or heavy code loading the processor (e.g. generating on-the-fly complex tree data structures, such as category structure or preparing thumbnail images before displaying the view without the use of caching mechanisms).
2. Use a Content Delivery Network (CDN). This is the use of server networks scattered around the world which provide content such as CSS, JS files and photos from servers located closest to the person who wants to view a given website. Thanks to CDN, resources are not queued, as in the case of classic servers, and are downloaded almost in parallel. The implementation of CDN reduces TTFB time up to 50%.
3. If you use shared hosting, consider migrating to a VPS server with guaranteed resources such as memory or processor power, or a dedicated server. This ensures only you can influence the operation of a machine (or a virtual machine in the case of VPS). If something works slowly, the problems may be on your side, not necessarily the server.
4. Think about implementing caching systems. In the case of WordPress, you have many plugins to choose from, the implementation of which is not problematic, and the effects will be immediate. WP Super Cache and W3 Total Cache are the plugins I use most often. If you use dedicated solutions, consider Redis, Memcache or APC implementations that allow you to dump data to files or store them in RAM, which can increase the efficiency.
5. Enable HTTP/2 protocol or, if your server already has the feature, HTTP/3. Advantages in the form of speed are impressive.
DOM processing time
DOM processing time is the time to download all HTML code. The more effective the code, the less resources needed to load it. The smaller amount of resources needed to store a website in the search engine index improves speed and user satisfaction.
I am a fan of reducing the volume of HTML code by eliminating redundant HTML code and switching the generation of displayed elements on a website from HTML code to CSS. For example, I use the pseudo classes :before and :after, as well as removing images in the SVG format from HTML (those stored inside <svg> </svg>).
Page rendering time
Page rendering time of a website is affected by downloading graphic resources, as well as downloading and executing JS code.
Minification and compression of resources is a basic action that speeds up the rendering time of a website. Asynchronous photo loading, HTML minification, JavaScript code migration from HTML (one where the function bodies are directly included in the HTML) to external JavaScript files loaded asynchronously as needed. These activities demonstrate that it is good practice to load only the Javascript or CSS code that is needed on a current sub-page. For instance, if a user is on a product page, the browser does not have to load JavaScript code that will be used in the basket or in the panel of a logged-in user.
The more resources needing to be loaded, the more time the Google Bot must spend to handle the download of information concerning the content of the website. If we assume that each website has a maximum number/maximum duration of Google Bot visits – which ends with indexing the content – the fewer pages we will be able to be sent to the search engine index during that time.
Crawl Budget Rank
The final issue requires more attention. Crawl budget significantly influences the way Google Bot indexes content on a website. To understand how it works and what the crawl budget is, I use a concept called CBR (Crawl Budget Rank) to assess the transparency of the website structure.
If Google Bot finds duplicate versions of the same content on a website, our CBR decreases. We know this in two ways:
1. Google Search Console
By analyzing and assessing problems related to page indexing in the Google Search Console, we will be able to observe increasing problems in the Status > Excluded tab, in sections such as:
- Website scanned but not yet indexed
- Website contains redirection
- Duplicate, Google has chosen a different canonical page than the user
- Duplicate, user has not marked the canonical page
2. Access Log
This is the best source of information about how Google Bot crawls our website. On the basis of the log data, we can understand the website’s structure to identify weak spots in architecture created by internal links and navigation elements.
The most common programming errors affecting indexation problems include:
1. Poorly created data filtering and sorting mechanisms, resulting in the creation of thousands of duplicate sub-pages
2. “Quick view” links which in the user version show a pop-up with data on the layer, and create a website with duplicate product information.
3. Paging that never ends.
4. Links on a website that redirect to resources at a new URL.
5. Blocking access for robots to often repetitive resources.
6. Typical 404 errors.
Our CBR decreases if the “mess” of our website increases, which means the Google Bot is less willing to visit our website (lower frequency), indexes less and less content, and in the case of wrong interpretation of the right version of resources, removes pages previously in the search engine index.
The classic crawl budget concept gives us an idea of how many pages Google Bot crawls on average per day (according to log files) compared to total pages on site. Here are two scenarios:
1. Your site has 1,000 pages and Google Bot crawls 200 of them every day. What does it tell you? Is it a negative or positive result?
2. Your site has 1,000 pages and Google Bot crawls 1,000 pages. Should you be happy or worried?
Without extending the concept of crawl budget with the additional quality metrics, the information isn’t as helpful as it good be. The second case may be a well-optimized page or signal a huge problem. Assume if Google Bot crawls only 50 pages you want to be crawled and the rest (950 pages) are junky / duplicated / thin content pages. Then we have a problem.
I have worked to define a Crawl Budget Rank metric. Like Page Rank, the higher the page rank, the more powerful outgoing links. The bigger the CBR, the fewer problems we have.
The CBR numerical interpretation can be the following:
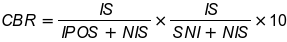
IS – the number of indexed websites sent in the sitemap (indexed sitemap)
NIS – the number of websites sent in the sitemap (non-indexed sitemap)
IPOS – the number of websites not assigned in the sitemap (indexed pages outside sitemap)
SNI – the number of pages scanned but not yet indexed
The first part of the equation describes the state of a website in the context of what we want the search engine to index (websites in the sitemap are assumed to be the ones we want to index) versus the reality, namely what the Google Bot reached and indexed even if we did not want that. Ideally, IS = NIS and IPOS = 0.
In the second part of the equation, we take a look at the number of websites the Google Bot has reached versus the actual coverage in indexing. As above, under ideal conditions, SNI = 0.
The resulting value multiplied by 10 will give us a number greater than zero and less than 10. The closer the result is to 0, the more we should work on CBR.
This is only my own interpretation based on the analysis of projects that I have dealt with this past year. The more I manage to improve this factor (increase CBR), the more visibility, position and ultimately the traffic on a website is improved.
If we assume that CBR is one of the ranking factors affecting the overall ranking of the domain, I would set it as the most important on-site factor immediately after the off-site Page Rank. What are unique descriptions optimized for keywords selected in terms of popularity worth if the Google Bot will not have the opportunity to enter this information in the search engine index?
User first content
We are witnessing another major revolution in reading and interpreting queries and content on websites. Historically, such ground-breaking changes include:
- Quantity standards – 1,000 characters with spaces and three money keywords in the content. Up to a certain moment, it was a guarantee of success, one day it simply ceased to matter.
- Thin content – traffic built on tags packed with keywords. Overnight, this strategy stopped working, as did artificially generated low-quality content (text mixers).
- Duplicate content – the Google Bot has learned (more or less well) which text indexed in the search engine is original (created first), and which is a copy. As a consequence, Panda (Google algorithm) was created. Every few months it filtered and flagged low-quality websites and reduced their ranking, as well as search engine positions. Currently, it works in “live” mode.
- Rank Brain – an algorithm that, using machine learning, interprets the queries of search engine users with less emphasis on keywords, and more on query context (including query history), as well as displays more context-specific results.
- E-A-T – elimination of content that is misleading or likely to be misleading due to the low authority of the author of the content, and thus the domains. This particularly affected the medical and financial industry. Any articles not created by experts, yet concerning the above spheres of life, can cause a lot of damage. Hence the fight of Google with domains containing poor content and quality.
Creating content for specific keywords is losing importance. Long articles packed with sales phrases lose to light and narrowly themed articles if the content is classified as one that matches the intentions of a user and the search context.
BERT
BERT (Bi-directorial Encoder Representations from Transformers) is an algorithm that tries to understand and interpret the query at the level of the needs and intentions of a user. For example, the query – How long can you stay in the US without a valid visa? – can display both the results of websites where we can find information on the length of visas depending on the country of origin (e.g. for searches from Europe), as well as those about what threatens the person whose visa will expire, or describing how to legalize one’s stay in the US.
Is it possible to create perfect content? The answer is simple – no. However, we can improve our content.
In the process of improving content so that it is more tailored, we can use tools such as ahrefs (to build content inspirations based on competition analysis), semstorm (to build and test longtail queries including e.g. search in the form of questions) and surferseo (for comparative analysis content of our website with competition pages in SERP), which has recently been one of my more favorite tools.
In the latter, we can carry out comparative analysis at the level of words, compound phrases, HTML tags (e.g., paragraphs, bolds and headers) by pulling out common “good practices” that can be found on competition pages that pull search engine traffic into themselves.
This is partly an artificial optimization of content, but in many cases, I was able to successfully increase the traffic on the websites with content I modified using the data collected by the above tools.
Conclusion
As I always highlight, there is no single way to deal with SEO. Tests demonstrate to us whether the strategy, both concerning creating the content of a website or the content itself, will prove to be good.
Under the Christmas tree and on the occasion of the New Year, I wish you high positions, converting movement and continuous growth!
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
About The Author

“Do not accept ‘just’ high quality. Anyone can do that. If the sky is the limit, find a higher sky.” Max Cyrek is CEO of Cyrek Digital, a digital marketing consultant and SEO evangelist. Throughout his career, Max, together with his team of over 30, has worked with hundreds of companies helping them succeed. He has been working in digital marketing for nearly ten years and has specialized in technical SEO, managing successful marketing projects.